
Anthony Song
- Undergraduate Student
- Department of CS, Department of ECE
- College of Engineering
- Cornell University
- ✉ Email: abs343 [at] cornell [dot] edu
I am an undergraduate student at Cornell University, pursuing dual degrees in Electrical Engineering and Computer Science. I have interned at AMD, contributing to verification / diagnostics tools for AI Engine Compilers. Outside of academics, I am big fan of basketball, sketching, origami, photography, and cooking. I am also a big foodie so feel free to reach out to me if you have any recommendations!
I am fortunate to be advised by Prof. Zhiru Zhang in the Computer Systems Laboratory. Previously, I worked with Prof. Tapomayukh Bhattacharjee at EmPRISE Lab and Prof. Maja Matarić at the Interaction Lab.
News
Education
Cornell University
B.S. in Electrical Engineering & Computer Science
Aug 2023 – May 2027

Work Experience
Zhang Research Group — Cornell University
Research Assistant
Hardware Accelerators for Linear Transformations
Advisor: Zhiru Zhang
Aug 2024 – Present

Advanced Micro Devices
AI Software Engineer Intern
Automated Diagnostics Tools for AI Engine Compilers
Mentors: Keshav Gurushankar, Bin Tu
May 2025 – Aug 2025
EmPRISE Lab — Cornell University
Research Assistant
Robot Systems Design for Assisted Feeding
Advisor: Tapomayukh Bhattacharjee
Dec 2023 – May 2025
Interaction Lab — University of Southern California
Research Intern
Visual Simultaneous Localization and Mapping
Advisor: Maja Matarić
May 2024 – Aug 2024

Publications
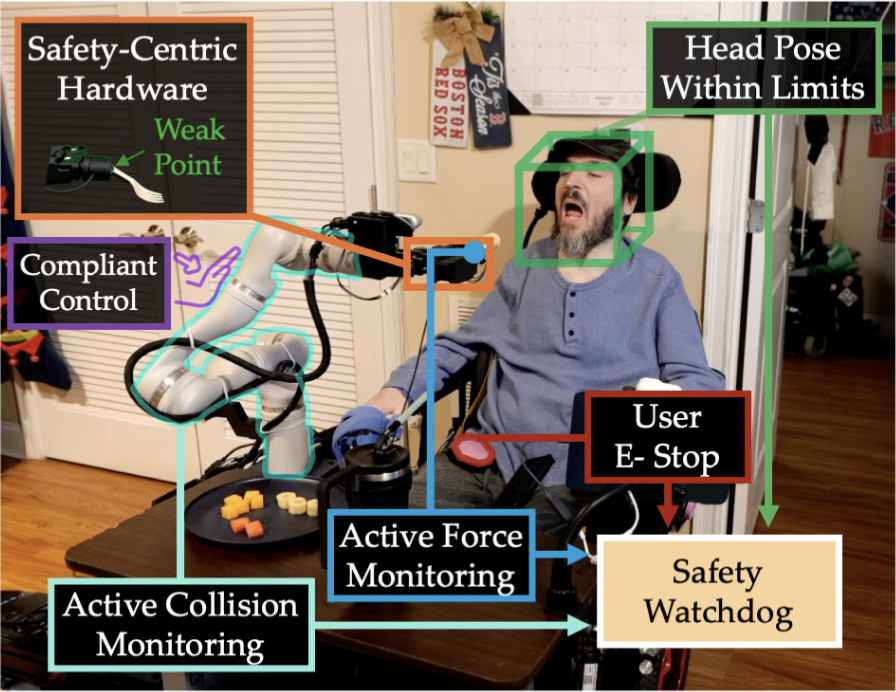
FEAST: A Flexible Mealtime-Assistance System Towards In-the-Wild Personalization
RSS, 2025
(Best Paper Award, Best Systems Paper Finalist)
[abs] [project] [paper] [code]
Projects

VeriLens
Coming Soon...
ABAX: ASIC Backend for Allo in XLS
Allo-to-XLS Compiler Backend to Support ASIC Flow
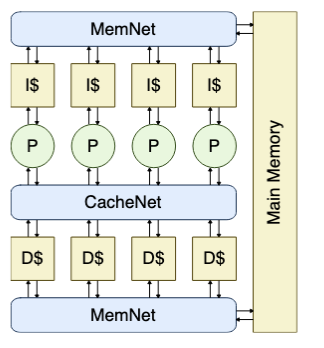
Multicore Processor
A Quad-Issue 5-Stage Pipelined Processor in SystemVerilog

Efficient Lane Detector for Autonomous Model Cars
ISLPED 2022 Design Contest Submission — Pruned ResNet18 Lane Detector + Model Autonomous Car
Teaching
- ECE 2300: Digital Logic and Computer Organization, TA, Fall 2026
- ECE 5760: Hardware Acceleration via FPGA, TA, Spring 2026
- ECE 2300: Digital Logic and Computer Organization, TA, Fall 2025
- ECE 2300: Digital Logic and Computer Organization, TA, Spring 2025
- CS 2800: Discrete Structures, TA, Fall 2024